Retrieval Augmented Generation from Scratch: Inception RAG
Explore vector embeddings, semantic search, chunking and more building an open-source RAG app
“Downwards is the only way forwards.”
As Large Language Models (LLMs) have become more intelligent and widely used, Retrieval Augmented Generation (RAG) has emerged as a very powerful technique to enhance their capabilities and help with their limitations.
To really understand how RAG works, in this post we are going to dive down and build a RAG system from scratch using Python and only open-source tools. We will use the open-source Llama 3 model, powered by the incredibly fast Groq platform, and the open-source Nomic embeddings. And we will not use complex libraries, frameworks like Langchain, or even vector databases. We will build the functionality from scratch with Python and some Numpy.
And our goal? A basic RAG system capable of answering questions about Christopher Nolan’s cult film Inception, using its screenplay as our knowledge base. By the end, you will have a clear understanding of how RAG works and the ability to implement it in your own projects. And you will also be aware of the issues and limitations of basic RAG and possible ways to improve it.
Let’s begin!
What is Retrieval Augmented Generation?
Large Language Models like GPT-4 or Llama 3 have a broad general knowledge and very advanced capabilities. They excel at understanding, processing and generating text, and are really useful as conversational assistants. But they have some limitations:
- Their knowledge is static and they might not know about specific topics or recent events.
- They have a limited context window (the maximum text a LLM can process including input and output), so you can’t feed them all the information you want.
- There’s no easy way to integrate your own personal or organization data into their knowledge, and it’s even harder if your data is always changing.
- They sometimes “hallucinate” answers that sound coherent but are incorrect or even nonsensical.
Retrieval Augmented Generation has proven to be a very effective technique (or rather, a family of techniques) to address these problems. RAG combines the power of LLMs with external knowledge retrieval, making it possible for language models to access relevant information when generating responses and not be constrained only by the knowledge they were trained on.
Applying RAG means that you can now integrate information about recent events, niche topics and your own personal and organization data into your LLM-based applications and make it actionable. It also means that this external knowledge base is no longer static, and it can adapt as your data changes or your business evolves.
RAG also allows you to have a greater control over which data the LLM uses in each generation. For example, you might want to prioritize your organization’s more accurate and specialized data when answering questions over the LLM’s general and potentially incomplete knowledge.
In the next sections, we will see how to achieve this by building a RAG system from the ground up. The Inception screenplay will serve as the knowledge base for a basic assistant that can answer questions about the movie. And we will look in detail at the different steps of the RAG pipeline. A quick preview:
- Loading: Import and parse the source documents.
- Chunking: Break the documents down into smaller, manageable pieces of text.
- Vector Embeddings: Convert the text chunks into numerical representations that encode their semantic meaning.
- Semantic Search: Use vector embeddings to find the pieces of text that are most semantically similar to a search query.
- Vector Store: Create a custom storage system that holds our vector embeddings and can perform semantic search.
- Retrieval Augmented Generation: Tie all the components together to take a user question, embed it, use the vector store to search for the most relevant information, and answer the question with the LLM using the relevant information as context.
You can find all the code in this GitHub repository with an MIT license to use it as you want.
Loading Documents
The first step in the RAG pipeline is to load and parse the information that we want to include in our knowledge base. In our case, it’s the Inception screenplay in pdf format, but we will generalize the code to any pdf files included in the DOCS_DIR folder, and it can be easily extended to other formats as well. To extract the text from the pdf files we’ll be using the pdfminer Python library.
from pdfminer.high_level import extract_text
docs = []
for filename in os.listdir(DOCS_DIR):
if filename.endswith('.pdf'):
file_path = os.path.join(DOCS_DIR, filename)
text = extract_text(file_path)
docs.append(text)Tokens
LLMs (and also embedding models) process text in basic units known as tokens. Depending on the model and the tokenization process used, tokens could be words, subwords or characters. You can explore how language models tokenize text with OpenAI’s tokenizer tool:
Because tokens are the basic units of LLM text processing, you will generally see inputs, outputs, context windows and chunk sizes measured in tokens. Keep also in mind that different models use different tokenization processes. In particular, Llama 3 uses a Byte-Pair Encoding (BPE) tokenizer which is based on tiktoken (the tokenizer used by OpenAI’s models), which is different to the SentencePiece tokenizer used by Llama 2.
Chunking
As seen before, large language models have a limited context window, which means that we need to be selective about the context included when answering a specific question. RAG helps solve this by splitting the source documents into chunks, converting each chunk into a vector embedding that encodes its meaning, and then using semantic search to find the most relevant chunks to the user question.
There are now two key questions: How do we split the documents? And what should be the size of the chunks?
To answer the first question, there are a number of possible techniques:
- Simple methods that split the text by a fixed number of characters.
- Recursive methods that split the text hierarchically using a list of separators or splitting functions.
- Specialized methods that take into account the document format (e.g. markdown or code).
- More advanced methods like semantic chunking (proposed by Greg Kamradt), where vector embeddings are used to split the text into chunks of semantically similar text.
You can learn more about these methods by reading Greg’s amazing 5 Levels Of Text Splitting notebook and watching his Youtube tutorial, or reading this article by Pinecone on chunking strategies.
The second crucial question is how large should the chunks be. Smaller chunks (for example, a single sentence) will capture well nuances in meaning and allow you to find very precise information, but may miss important context that will be scattered across neighboring chunks. Larger chunks (multiple pages of text, for instance) will include broader context and themes, but may also include irrelevant information and dilute the specific meaning of individual sentences.
This is a very important decision and unfortunately there is not a one-size-fits-all recipe. In general, you should evaluate different chunk sizes for your own application and see the one that gives you the optimal balance and the best results. In practice, somewhere between 512-1024 tokens seems to be a sweet spot for many applications.
In our RAG system, we’ll be using a recursive chunking method inspired by LlamaIndex’s Sentence Splitter with a chunk size of 512 tokens. Let’s take a look at some of the TextSplitter code:
class TextSplitter:
def __init__(self, chunk_size):
self.chunk_size = chunk_size
self.splitters = [
partial(split_by_separator, sep='\n\n'),
partial(split_by_separator, sep='\n'),
split_sentences,
partial(split_by_separator, sep=' ')
]
def split(self, text):
splits = self._split_recursive(text)
chunks = self._merge_splits(splits)
return chunks As you can see above, there are 4 splitting functions applied hierarchically which break down text into paragraphs (ending in a double newline), lines ending in a newline character, sentences and words, respectively. To split sentences we are using NLTK’s amazing Punkt Sentence Tokenizer.
The splitting is performed recursively by the _split_recursive function, starting with the largest splits (paragraphs), and only splitting into smaller units when the split size (in tokens) is larger than the specified chunk_size. Then the _merge_splits function merges the splits together into the final chunks ensuring that all chunks have a size as close as possible to the specified chunk_size but never exceeding it.
And this is how we can use the TextSplitter to chunk the documents that we loaded previously:
chunks = []
text_splitter = TextSplitter(chunk_size=512)
for i, doc in enumerate(docs):
doc_chunks = text_splitter.split(doc)
chunks += doc_chunksIf you want to look at the text splitting code and the implementation of the rest of the functions in detail, you can find it here.
Vector Embeddings
Vector Embeddings are one of the most incredible and useful concepts in AI. They allow us to represent phrases, paragraphs and even entire documents as numerical vectors in a high-dimensional space. And the most important quality of this representation is that it captures semantic similarity, meaning that pieces of text that have similar meanings are closer together in this vector space.
To get a better intuition about embeddings, check the Tensorflow Embedding Projector. This tool displays high-dimensional embeddings into a simple 3D view that captures the key properties of the data. With word embeddings, for example, you can explore which words are semantically closer to a specific word. Let’s see the plot for the word “intelligence”:
But the power of embeddings is not limited to text. They can also represent images, audio and other formats. By converting different types of information into embeddings in the same vector space, you can capture meanings and connections across them and be able to search for content in all these formats.
In our RAG system, we are using Nomic Embed, a recently released and fully open-source embedding model that outperforms well-known embedding models like OpenAI’s Ada-002 and text-embedding-3-small on both short and long context tasks.
Embedding the text chunks generated in the previous step is straightforward with Nomic’s Python client:
from nomic import embed
embed_res = embed.text(
texts=chunks,
model='nomic-embed-text-v1.5',
task_type='search_document',
inference_mode='local'
)
print(embed_res['embeddings'])For each text chunk that you embed with Nomic’s model, you will get as output a vector of 768 coordinates that encodes the chunks’s semantic content. The inference_mode='local' option means that we are running the model locally in our computer, but Nomic also provides a remote API for more performant use cases.
Semantic Search
Now that we have split the Inception screenplay into chunks and converted them into vector embeddings that encode the meaning of those chunks, we can perform semantic search to find the text chunks that are most similar to a specific user query. But how does semantic search actually work?
If you remember, vector embeddings capture semantic similarity by grouping pieces of text that have a similar meaning closer together in the vector embedding space. So to do semantic search, we only need to convert the user query into a vector embedding too, and find which vector embeddings from the source documents are closer or most similar to the query embedding.
There are several methods to measure the distance or similarity between vectors: Euclidean distance (the straight-line distance between two vectors), dot product (the sum of the products of the vector components) or cosine similarity (a measure of the angle between the vectors).
Cosine similarity is commonly used as it is invariant to vector magnitudes (it measures the angle between the vectors), it’s suitable for high-dimensional data and it’s very easy to interpret. The result of cosine similarity ranges from -1 to 1, where 1 means the angle between the vectors is 0 (they are identical in direction and as similar as possible), 0 means they are orthogonal (uncorrelated), and -1 means they point in opposite directions. Although in practice and depending on the embedding model, the actual range of values might be from 0 to 1, or narrower.
Cosine similarity is calculated by dividing the dot product of two vectors by the product of their magnitudes, and it equals the cosine of the angle between the vectors:
And this is how to implement it in code using the NumPy library:
def cosine_similarity(query_vector, vectors):
query_vector = np.array(query_vector)
vectors = np.array(vectors)
return np.dot(vectors, query_vector) / (np.linalg.norm(vectors, axis=1) * np.linalg.norm(query_vector))Note how the function uses a vectorized approach to calculate the cosine similarity between the query vector and a list of vectors simultaneously. This takes advantage of NumPy’s efficient array operations that are much faster than calculating the similarities one by one in a loop.
Using the cosine_similarity function, we can perform semantic search by calculating the similarities between the user query embedding and all the document chunks embeddings, and then selecting the chunks with the highest similarity scores.
Vector Store
A vector store is a special database designed to store and search through large collections of vector embeddings. There are several popular vector database providers like Qdrant, Pinecone, Chroma, Weaviate or even PostgreSQL with the pgvector extension, most of which are also open-source. These solutions offer great performance, high scalability and advanced querying functionalities, and are very useful for large RAG systems.
However, for our simple RAG application, we are going to build a very basic but effective vector store from scratch that will also allow us to understand the key concepts. In our simple implementation, we are going to store the vector embeddings and their corresponding text chunks as a list of dictionaries like this one:
{"vector": [0.1, 0.4, ...], "text": "This is the text chunk."}
Let’s take a look at its implementation:
class VectorStore:
def __init__(self):
self.store = []
def add(self, items):
self.store.extend(items)
def save(self, file_path=VECTOR_STORE_FILEPATH):
with open(file_path, 'w') as f:
json.dump(self.store, f)
def load(self, file_path=VECTOR_STORE_FILEPATH):
with open(file_path, 'r') as f:
self.store = json.load(f)
def query(self, vector, top_k=10):
vectors = [item['vector'] for item in self.store]
similarities = cosine_similarity(vector, vectors)
top_k_indices = np.argsort(similarities)[-top_k:][::-1]
return [{**self.store[i], 'score': similarities[i]} for i in top_k_indices]The most important method is the query method and it’s the one used for semantic search. It takes a vector embedding as input (for example, the embedded user query), calculates the similarities between this query vector and all the vectors in the vector store, and returns the top k most similar chunks including the score.
If you are curious about the details, NumPy’s argsort returns the indices of the sorted similarities (in ascending order). We are interested in the top k highest similarities (in descending order), so we take the last k indices and reverse them. We then use these indices to retrieve the corresponding items from our store, returning the vector, the text chunk and the similarity score for each of the top k.
The add method simply appends a list of items (the dictionaries containing the vector embedding-text chunk pairs) to the vector store. And the save and load methods allow us to save the vector store to and load it from a JSON file.
And this is how we use our vector store to add the vector embeddings and text chunks generated in the previous step and save it for future use:
vector_store = VectorStore()
vectors = [
{'vector': vector, 'text': text} for vector, text in zip(embed_res['embeddings'], chunks)
]
vector_store.add(vectors)
vector_store.save()Retrieval Augmented Generation
We have explored all the necessary building blocks of a RAG system. Now let’s bring them together to create an application that can answer questions about Inception (or any other documents you would like use in your own app).
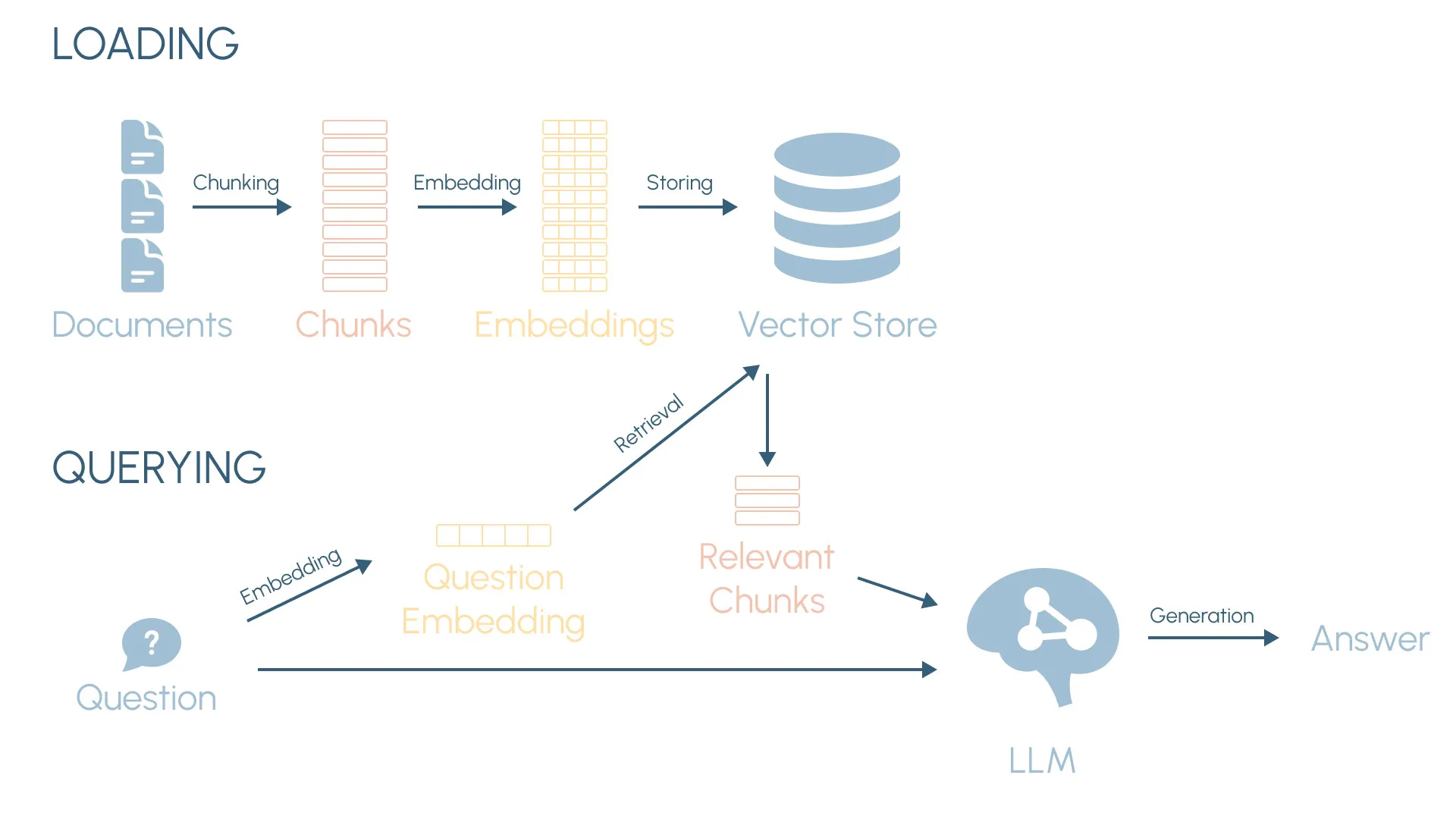
The core idea of RAG is very simple:
- Take a user’s question and convert it to a vector embedding.
- Use semantic search to retrieve the most relevant chunks to the user question from the vector store.
- Include these chunks as context for the language model to generate an answer based on them.
Let’s now see this in actual code:
def answer_question(question, vector_store):
# Embed the user's question
embed_res = embed.text(
texts=[question],
model='nomic-embed-text-v1.5',
task_type='search_query',
inference_mode='local'
)
query_vector = embed_res['embeddings'][0]
# Find the most relevant chunks in our vector store using semantic search
chunks = vector_store.query(query_vector)
# Prepare the context and prompt, and generate an answer with the LLM
context = '\n\n---\n\n'.join([chunk['text'] for chunk in chunks]) + '\n\n---'
user_message = USER_PROMPT.format(context=context, question=question)
messages=[
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': user_message}
]
chat_completion = groq_client.chat.completions.create(
messages=messages, model='llama3-70b-8192'
)
return chat_completion.choices[0].message.contentWe have already seen how to embed text and perform semantic search in our vector store using the query method. The new element here is how we use Meta’s Llama 3 language model (specifically the larger, more powerful 70B version), powered by Groq, to generate answers. And because Llama 3 is open-source, you can also deploy it in your own hardware without Groq if you prefer.
If it’s your first time using LLMs like Llama 3, you can check this introduction section in my previous series on building an AI voice assistant.
Essentially, we pass two messages to the LLM:
- A basic system message that sets the overall behavior.
- A user message containing the user question, the most relevant chunks from our vector store and specific instructions for answering the question.
A crucial instruction for LLMs in RAG systems is to answer the user questions using ONLY the provided context, and never making answers up if they are not found in the context. Here is the actual user prompt template:
USER_PROMPT = """
Use the following pieces of context to answer the user question.
You must only use the facts from the context to answer.
If the answer cannot be found in the context, say that you don't have enough information to answer the question and provide any relevant facts found in the context.
Don't address \"the context\" explicitly in your answer, answer the question like it's your own knowledge.
Context:
{context}
User Question:
{question}
"""Note that we are using Python’s string formatting to fill the user prompt template with the relevant context (the retrieved chunks) and the user question:
USER_PROMPT.format(context=context, question=question)And to complete our RAG application, we create a main function that loads the vector store from the JSON file and starts a simple loop for handling multiple user questions:
def main():
vector_store = VectorStore()
vector_store.load()
print("Ask a question about Christopher Nolan's Inception movie:\n")
while True:
question = input()
answer = answer_question(question, vector_store)
print(answer, '\n')Evaluation
Now that our RAG system is complete, let’s test it with some questions about Inception:
1. What’s the most resilient parasite?
According to Cobb, the most resilient parasite is an idea. He says, “Resilient, highly contagious. Once an idea’s taken hold in the brain it’s almost impossible to eradicate. A person can cover it up, ignore it - but it stays there.”
2. What’s the name of Cobb’s wife?
Cobb’s wife’s name is Mal.
3. What’s the name of the Fischer’s family business?
The name of Fischer’s family business is Fischer Morrow.
4. What happened to Mal?
Mal, Cobb’s wife, died by jumping off a ledge in a hotel. This event occurred before the main storyline of the script. Cobb was unable to stop her from jumping, and her death has had a profound impact on him. Throughout the script, it is revealed that Mal’s death was a result of Cobb’s own actions, as he had performed an inception on her, planting the idea that their reality was not real. This led to her becoming convinced that they needed to “wake up” from their reality, and ultimately, to her death.
5. What was Fisher’s relationship with his father like?
According to the script, Robert Fischer’s relationship with his father, Maurice Fischer, was strained and disappointing. In a conversation with Peter Browning, Fischer reveals that his father told him “there’s really nothing to be said” when he went to him in grief after his mother’s death. Fischer was only 11 years old at the time. Later, when Fischer’s father was on his deathbed, he called Fischer to his side and his last words to him were “Disappointed.” This implies that Fischer’s father was emotionally distant and critical, and that Fischer felt unsuccessful in gaining his father’s approval or affection.
Overall we can see that the system accurately answers a range of questions about Inception, from simple facts to more complex questions about characters’ relationships and plot points, and is able to integrate multiple pieces of information to provide more complete answers.
Limitations of Basic RAG and Potential Improvements
“You mustn’t be afraid to dream a little bigger, darling.”
Our basic built-from-scratch RAG application is a good starting point and very helpful to understand the essential elements and concepts. However, as you start applying it to real-world use cases, you will quickly find a number of issues and limitations. Let’s end this post exploring some of them and opening up possible avenues for improvement:
-
COMPLEX QUERIES: Our current system works well for simple and factual questions, but will not work so well with complex questions that require many pieces of information or a synthesis of whole documents. For example: “How does Cobb’s character evolve throughout the movie?” or “What are the main themes of Inception?”. You are always limited by the amount of information you can retrieve and by the context window of the LLM.
✅ Improvements: Break down complex questions into simpler sub-queries, use multiple rounds of iterative retrieval to gather enough relevant information before generating the answer, or use recursive summarization techniques to synthesize whole documents.
-
SEMANTIC GAP: The effectiveness of retrieval depends heavily on how the user phrases the question and whether there is enough information in the question to connect it with the relevant chunks using semantic search. If the semantic gap is too large, these chunks may not be fetched or may rank lower than less relevant chunks that share more semantic similarities with the question.
✅ Improvements: Query rewriting or query expansion (using an LLM to rewrite the query or generate multiple variations of the query), hybrid retrieval (combining semantic search with the more traditional keyword-based search) or iterative retrieval.
-
LARGER DATASETS: As the knowledge base grows (for instance, all of Christopher Nolan’s screenplays), it will become harder to retrieve the correct chunks for specific questions and the LLM context might be polluted by chunks that might not even belong to the movie you are asking about.
✅ Improvements: Use metadata filtering to narrow down the search space (e.g. movie title, date, characters), or use a two-step retrieval where the LLM first tries to route the question to a specific document or subset of documents.
-
RETRIEVAL QUALITY: Some retrieved chunks might not be relevant or the order might not be the optimal one. This is a common issue with vector databases and large datasets, as they use approximate similarity search techniques that trade off some accuracy for speed.
✅ Improvements: Implement a reranking step after initial retrieval with a specialized model that is able to sort the chunks more accurately.
-
CONVERSATION MEMORY: Our current system treats each question independently and is not suitable for follow-up questions or questions that reference previous interactions. For example, asking “Who’s Ariadne?” followed by “What’s her role in the team?”
✅ Improvements: Implement a conversational RAG system that includes the conversation history in the LLM context and use the LLM to rephrase the question based on the previous interactions.
-
SCALABILITY: The basic vector store we built from scratch works well for simple use cases but lacks the efficiency and performance required for applications with large datasets.
✅ Improvements: Implement more advanced search indexes and similarity search algorithms (like HNSW), or use one of the popular vector databases mentioned earlier.
As you can see, even though we covered a lot in this post, there is much more to explore in the world of Retrieval Augmented Generation, especially when it comes to applying it to real-world use cases. And because it’s a new and rapidly growing field, there is also new research emerging constantly. In future posts, we will continue exploring more sophisticated RAG systems and techniques.
Meanwhile, the code for this project is available on GitHub. And if you have any questions or comments, you can reach me at [email protected].