Building an AI Voice Assistant with Groq and Deepgram (Part 2)
A Python backend with FastAPI & WebSockets
Welcome to the second part of this 3-part series on building a fast and interactive voice assistant using Python, React, Deepgram, Llama 3 and Groq. A quick recap of the roadmap:
- Part 1: A local Python voice assistant app.
- Part 2: A Python backend with FastAPI & WebSockets.
- Part 3: An interactive React user interface.
In Part 1 we built a local Python application that showed the core features of an AI voice assistant. It could transcribe speech to text, generate responses using a language model (LLM), and convert the text back to speech. This was a great starting point to understand the basic building blocks.
However, to make our voice assistant accessible to other people, we need to create a web application. This will make it reachable online and allow multiple users to interact with it simultaneously.
In this second part of the series, we’ll build the Python backend for the voice assistant web app. We’ll use FastAPI and WebSockets to allow real-time communication between the clients and the server, making the experience interactive.
We’ll begin with a high-level overview of the backend.
1. High-Level Overview
The voice assistant web app consists of a client application that interacts with a backend server. The client sends audio data of the user’s speech to the server, which then processes the audio, generates a response, and sends it back to the client. This communication happens in real-time, thanks to the power of WebSockets.
As we saw in Part 1, the voice assistant has three main blocks:
- Speech-to-Text transcription using Deepgram Nova 2.
- A Large Language Model (LLM), Meta’s Llama 3 running on Groq, to generate human-like responses from the transcribed text.
- Text-to-Speech using Deepgram Aura to convert the responses into speech.
1.1. WebSockets: Real-time Communication
WebSockets are essential for real-time communication between the client and the server. Unlike traditional HTTP requests, which are unidirectional and require the client to initiate a request to receive a response, WebSockets create connections that stay open and are bidirectional.
Once a WebSocket connection is established, both the client and the server can send messages to each other at any time. This is particularly useful for our voice assistant, because it allows the client to continuously stream audio data to the server and receive transcripts and responses in real-time.
WebSockets support different data formats:
- Text Data: WebSockets can send plain text or JSON strings for structured data. In our application, we use JSON messages to transmit data like transcripts and control messages between the server and the client. For example, when a final transcript is generated, we send it to the client with this JSON format:
{"type": "transcript_final", "content": "The transcribed sentence..."}. - Binary Data: WebSockets also support binary data, like for instance audio streams. In our application, the client continuously sends the user’s speech to the server as binary data, and the server sends the audio response from the assistant back to the client in the same format.
By allowing the client and server to send data to each other as soon as it is available, WebSockets create a smooth and interactive user experience, which is essential for a voice assistant.
1.2. FastAPI and Asynchronous Python
To build the backend we use FastAPI, a fast and easy-to-use web framework for building APIs with Python. One of the key features of FastAPI is that it supports asynchronous code. As introduced in Part 1, asynchronous code allows us to perform multiple tasks at the same time without blocking the execution of other parts of the application.
In our voice assistant, we’ll use asynchronous programming to run two main tasks simultaneously:
- The
transcribe_audiotask that converts the user audio into text transcripts. - The
manage_conversationtask that handles the generated transcripts, calls the LLM to generate a response, converts the text response into speech, and sends the transcripts and responses back to the client.
Asynchronous programming in FastAPI is also important for handling multiple users interacting with the voice assistant at the same time without losing performance or responsiveness.
1.3. Client-Server Data Flow
To better understand the system, it’s worth taking a closer look at the data flow between the client and the server:
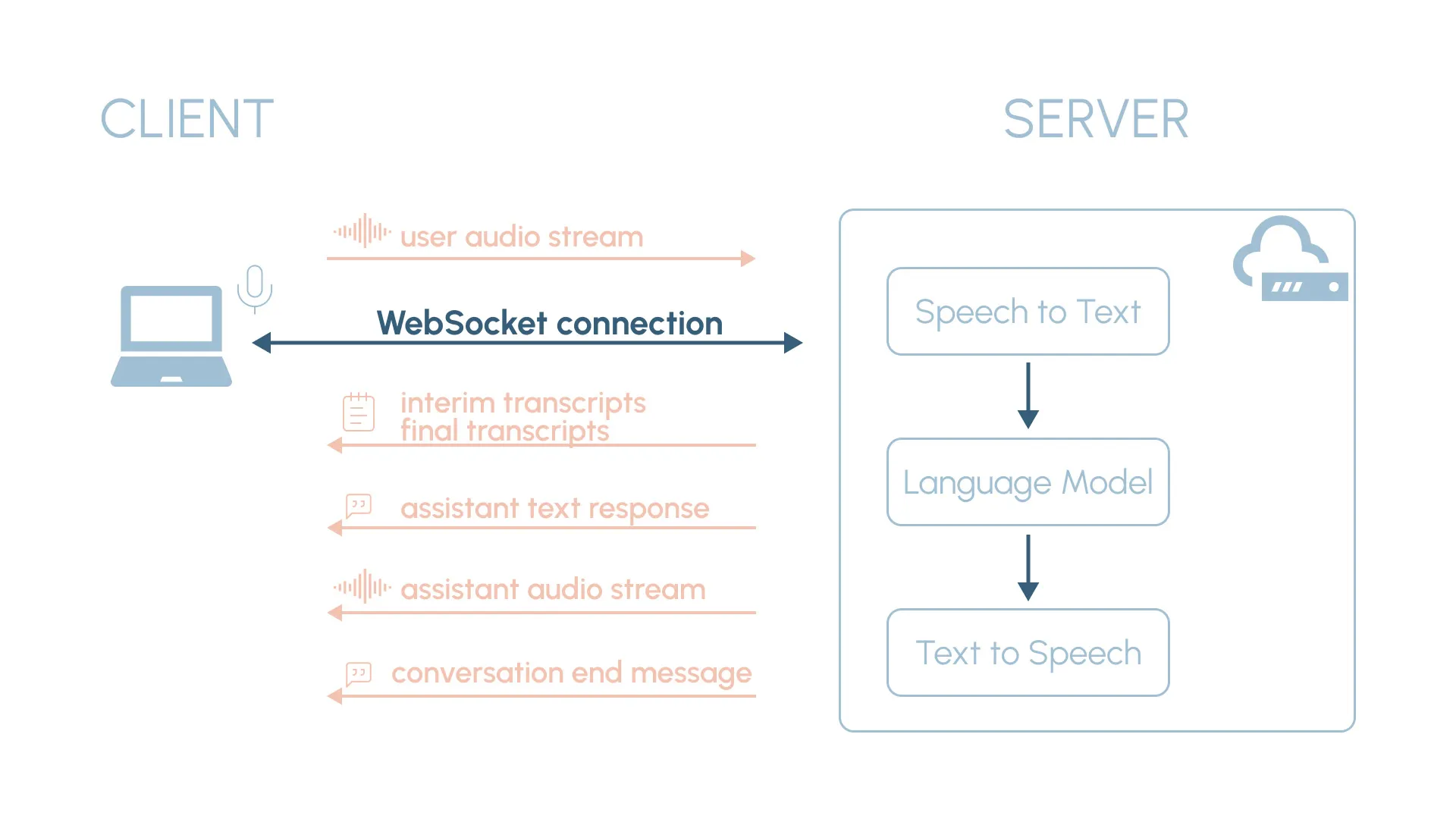
CLIENT ➜ SERVER
- User audio stream: When the user speaks, the client application captures the audio data and sends it to the server via the WebSocket connection as a binary stream.
SERVER ➜ CLIENT
- Interim transcripts: Preliminary transcripts generated as the user speaks, allowing the user to see the transcription in real-time. The server sends them to the client using a JSON message with the format
{"type": "transcript_interim", "content": ...}. - Final transcripts: Generated when maximum accuracy has been reached for a specific segment. They are sent as JSON messages to the client with the format
{"type": "transcript_final", "content": ...}. - Assistant text response: When the user stops speaking, the full transcript is sent to the LLM to generate a response. The assistant response is sent to the client as a JSON message with the format
{"type": "assistant", "content": ...}. - Assistant audio stream: The generated response is converted to speech and the audio stream is sent to the client as binary data.
- Conversation end message: If the user’s message ends with “bye” or “goodbye”, the server sends the special JSON control message
{"type": "finish"}, indicating that the conversation should end.
Note that we are not only sending the audio responses to the client, but also the text transcripts and responses. This will allow us to display the conversation text to the user.
2. Technical Deep Dive
Let’s now dive into the backend code. You can find it all in the backend/ folder of this GitHub repository.
2.1. Backend Project Structure
Let’s start by looking at the backend project structure:
backend/
├── app/
│ ├── __init__.py
│ ├── main.py
│ ├── config.py
│ ├── assistant.py
│ └── local_assistant.py
├── .env
└── pyproject.tomlapp/main.py: Entry point of our FastAPI application, where we define the WebSocket endpoint.app/config.py: Configuration settings for the application.app/assistant.py: File that defines theAssistantclass, containing the core logic of the assistant.app/local-assistant.py: Local assistant app covered in Part 1, not used in the FastAPI application..env: File storing environment variables with sensitive information like API keys.pyproject.toml: Project metadata and build dependencies configuration file.
2.2. FastAPI Setup and Configuration
Setting up a FastAPI application is very simple. In main.py, we create an instance of the FastAPI class and add CORS (Cross-Origin Resource Sharing) middleware to allow requests from specified origins:
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=settings.ALLOW_ORIGINS,
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)In config.py, we use Pydantic Settings to define the configuration variables and load sensitive values from the environmental variables in the .env file:
class Settings(BaseSettings):
ENVIRONMENT: str = 'development'
ALLOW_ORIGINS: str = '*'
GROQ_API_KEY: str
DEEPGRAM_API_KEY: str
model_config = SettingsConfigDict(env_file='.env')
settings = Settings()We can now easily access configuration values throughout our application using settings.<VARIABLE_NAME>.
2.3. WebSockets
It’s very simple to implement a WebSocket endpoint in FastAPI using the @app.websocket decorator:
@app.websocket('/listen')
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
try:
while True:
data = await websocket.receive_text()
await websocket.send_text(f'Message text was: {data}')
except WebSocketDisconnect:
print('Client disconnected')While not very practical, the example above highlights everything we need:
- The WebSocket endpoint is defined at the path
/listenand receives thewebsocketobject as a parameter. - When a client connects, the connection is accepted using
await websocket.accept(). - The while loop listens for incoming text messages using
await websocket.receive_text(), sending the same data back to the client withawait websocket.send_text(). - The
try/exceptblock is used to gracefully handle client disconnections by catching theWebSocketDisconnectexception.
Additionally, we can also use websocket.receive_bytes() / websocket.send_bytes() for binary data and websocket.receive_json() / websocket.send_json() for structured data in JSON format.
2.4. Initializing and Running the Assistant
Now that we understand how to use WebSockets, let’s take a look at the actual WebSocket endpoint of the voice assistant app:
@app.websocket('/listen')
async def websocket_listen(websocket: WebSocket):
await websocket.accept()
assistant = Assistant(websocket)
await assistant.run()Whenever a client starts a WebSocket connection with the server, we accept the connection, create an instance of the Assistant class, and then call the assistant’s main run() method. The Assistant class encapsulates the voice assistant logic.
This is how the assistant instance is initialized:
class Assistant:
def __init__(self, websocket, memory_size=10):
self.websocket = websocket
self.transcript_parts = []
self.transcript_queue = asyncio.Queue()
self.system_message = {'role': 'system', 'content': SYSTEM_PROMPT}
self.chat_messages = []
self.memory_size = memory_size
self.httpx_client = httpx.AsyncClient()
self.finish_event = asyncio.Event()The __init__ method initializes all the attributes that store the assistant’s state, that will be referenced and updated as the assistant runs:
websocket: The WebSocket connection object, which allows us to send and receive messages to/from the client.transcript_parts: The list that collects the transcript fragments until the end of the user speech is detected.transcript_queue: An asyncio Queue that will be used to pass transcript data between the two main concurrent tasks, as we will see shortly.system_message: The initial system message that sets the context for the conversation with the language model. It’s the same we used in Part 1.chat_messages: A list to store the conversation history, including both user and assistant messages.memory_size: The number of recent messages to keep in memory for context.httpx_client: An AsyncClient from the httpx library that will be used to make asynchronous requests to Deepgram’s text-to-speech API.finish_event: An asyncio Event to signal that the conversation should end.
And using a top-down approach, let’s examine the assistant’s main run() method:
async def run(self):
try:
async with asyncio.TaskGroup() as tg:
tg.create_task(self.transcribe_audio())
tg.create_task(self.manage_conversation())
except* WebSocketDisconnect:
print('Client disconnected')
finally:
await self.httpx_client.aclose()
if self.websocket.client_state != WebSocketState.DISCONNECTED:
await self.websocket.close()
The first thing to note is that we are using an asyncio TaskGroup to simultaneously run the two main tasks of the assistant: transcribe_audio and manage_conversation.
Task groups are a recent addition in Python 3.11 that offers a more convenient and reliable way to run and wait for concurrent tasks. The async with statement ensures that both tasks are properly managed and waited for until completion. Moreover, and unlike asyncio.gather, if any of the tasks exit with an exception (for example if the client disconnects), the other one will be automatically cancelled. This is particularly useful as we want to make sure that no tasks are left running if anything goes wrong.
If you are curious about the except* syntax, it’s used to handle ExceptionGroups. If any tasks of the TaskGroup fail, an ExceptionGroup will be raised combining all exceptions.
The finally clause allows us to clean up resources (like closing the httpx_client and the WebSocket connection if it wasn’t already closed by the client) when the tasks end or exit due to an exception.
2.5. Transcribe Audio Task
The transcribe_audio task is responsible for receiving the audio stream from the client through the WebSocket connection, sending it to Deepgram for transcription, and placing the transcripts into a queue for further processing by the manage_conversation task.
If you remember the transcribe_audio function of Part 1, you will find the code very similar:
async def transcribe_audio(self):
dg_connection = deepgram.listen.asynclive.v('1')
dg_connection.on(LiveTranscriptionEvents.Transcript, on_message)
dg_connection.on(LiveTranscriptionEvents.UtteranceEnd, on_utterance_end)
if await dg_connection.start(dg_connection_options) is False:
raise Exception('Failed to connect to Deepgram')
try:
while not self.finish_event.is_set():
data = await self.websocket.receive_bytes()
await dg_connection.send(data)
finally:
await dg_connection.finish()Like we did in Part 1, we create a WebSocket connection to Deepgram (dg_connection), we register the on_message and on_utterance_end event handlers, and we start the connection. The creation of the Deepgram client and all the configuration options were omitted as they were covered in depth in Part 1.
But unlike in Part 1, the transcribe_audio task now keeps running until self.finish_event.is_set() is true (the conversation end signal) or alternatively until the client closes the WebSocket connection, which will exit the task with a WebSocketDisconnect exception.
The data processing is also different. Instead of using a local microphone, we are receiving the user audio stream through the WebSocket connection with await self.websocket.receive_bytes() and then sending it to Deepgram for transcription with await dg_connection.send(data). The finally clause ensures that we close the connection at the end.
Let’s focus now on the on_message event handler that listens for the transcripts generated by Deepgram:
async def on_message(self_handler, result, **kwargs):
sentence = result.channel.alternatives[0].transcript
if len(sentence) == 0:
return
if result.is_final:
self.transcript_parts.append(sentence)
await self.transcript_queue.put({'type': 'transcript_final', 'content': sentence})
if result.speech_final:
full_transcript = ' '.join(self.transcript_parts)
self.transcript_parts = []
await self.transcript_queue.put({'type': 'speech_final', 'content': full_transcript})
else:
await self.transcript_queue.put({'type': 'transcript_interim', 'content': sentence})As seen in Part 1, there are three types of transcripts received:
- Interim or preliminary transcripts, generated in real-time as the user speaks.
- Final transcripts, generated when maximum accuracy has been reached for a specific segment.
- Speech final transcripts, generated when Deepgram detects that the user has finished speaking. This is when we join all the collected
transcript_partsinto thefull_transcript.
The key difference with Part 1 lies in how the transcripts are handled: we are now adding them to the transcript_queue. This allows the manage_conversation task to asynchronously process the transcripts as they are generated, while the transcribe_audio task continues to run concurrently. By utilizing this queue-based approach, we ensure that the audio transcription and conversation management tasks can operate independently and efficiently, leading to a smooth and responsive user experience.
2.6. Manage Conversation Task
The manage_conversation task is responsible for handling the conversation flow between the user and the AI assistant. It retrieves transcripts from the transcript_queue, processes them based on their type, generates responses using the language model and sends the transcripts and responses back to the client.
Let’s take a closer look at the code:
async def manage_conversation(self):
while not self.finish_event.is_set():
transcript = await self.transcript_queue.get()
if transcript['type'] == 'speech_final':
if self.should_end_conversation(transcript['content']):
self.finish_event.set()
await self.websocket.send_json({'type': 'finish'})
break
self.chat_messages.append({'role': 'user', 'content': transcript['content']})
response = await self.assistant_chat(
[self.system_message] + self.chat_messages[-self.memory_size:]
)
self.chat_messages.append({'role': 'assistant', 'content': response})
await self.websocket.send_json({'type': 'assistant', 'content': response})
await self.text_to_speech(response)
else:
await self.websocket.send_json(transcript)The task runs in a loop, asynchronously retrieving transcript messages from the transcript_queue as they arrive. The processing of the transcripts depends on their type:
- If it’s a
'speech_final'transcript (indicating that the user has finished speaking):- It first checks if the conversation should end with
should_end_conversation(if the user’s message ends with “bye” or “goodbye”). If true, it sets thefinish_eventto true to signal the end of the conversation, sends a JSON message with{'type': 'finish'}to the client, and breaks from the loop. - If it’s not the end of the conversation, the user’s message (the full transcript) is appended to the
chat_messageslist, which contains the conversation history, and theassistant_chatmethod is called to generate a response using the LLM. - The generated response is sent back to the client as a JSON message and also as audio after converting into speech using
text_to_speech.
- It first checks if the conversation should end with
- If the transcript is not a
'speech_final'transcript (e.g., an interim or final transcript), it is directly sent to the client as a JSON message, allowing the user to see the transcription in real-time.
The should_end_conversation and assistant_chat methods are identical to the ones in Part 1:
def should_end_conversation(self, text):
text = text.translate(str.maketrans('', '', string.punctuation))
text = text.strip().lower()
return re.search(r'\b(goodbye|bye)\b$', text) is not None
async def assistant_chat(self, messages, model='llama3-8b-8192'):
res = await groq.chat.completions.create(messages=messages, model=model)
return res.choices[0].message.contentThe text_to_speech method is now fully asynchronous and, instead of playing the audio response locally like in Part 1, it sends the audio stream to the client using the WebSocket connection in chunks of 1024 bytes:
async def text_to_speech(self, text):
headers = {
'Authorization': f'Token {settings.DEEPGRAM_API_KEY}',
'Content-Type': 'application/json'
}
async with self.httpx_client.stream(
'POST', DEEPGRAM_TTS_URL, headers=headers, json={'text': text}
) as res:
async for chunk in res.aiter_bytes(1024):
await self.websocket.send_bytes(chunk)2.7. Running the Code
To run the code for the voice assistant backend, follow these steps in your terminal or command-line interface:
-
Make sure you have Python (3.11 or higher) installed on your system.
-
Install Poetry, the package manager used in this project. You can find the installation instructions here.
-
Clone the GitHub repository containing the code, navigate to the backend folder and install the project dependencies:
git clone https://github.com/ruizguille/voice-assistant.git cd voice-assistant/backend poetry install -
Create a
.envfile in the backend folder copying the.env.examplefile provided and set the required environment variables:GROQ_API_KEY: Your Groq API key.DEEPGRAM_API_KEY: Your Deepgram API key.
-
Activate the virtual environment and start the FastAPI backend server:
poetry shell fastapi dev app/main.py
With the backend server up and running, we're one step closer to having a fully functional AI voice assistant. In Part 3, the final part of this series, **we'll bring everything together and build the frontend client using React!**