Advanced RAG for Talent Matching in Large Organizations
Find the perfect team from 1000+ professionals in minutes with AI
While there are many tutorials out there showing basic Retrieval Augmented Generation (RAG) implementations with simple document Q&A (including my own), real-world enterprise applications demand more sophisticated solutions. How do you take RAG beyond basic document retrieval and build an intelligent system that can actually help make decisions and add value to the business?
That’s exactly what I’ll explore in this post, walking you through an advanced RAG-based solution I recently designed for a large Spanish technology consulting company. The goal is to transform their project staffing process through intelligent talent matching and automatically generate client-ready presentations.
This project serves as a very practical example of how to define, structure, and build a RAG system that solves a real business problem, one that’s actively costing companies valuable time and money through inefficient manual processes.
The Business Challenge
How do you efficiently match the right talent to increasingly complex client projects when your talent pool keeps growing and changing? What works for a staff of 20 becomes unsustainable at 200 — and a nightmare over 1000.
Picture this: you’re a senior manager at a growing consultancy. A major bank needs a new team for their digital transformation initiative. The requirements are specific: a technical team lead with architecture expertise, a frontend engineer, a backend engineer and a data science specialist, all with prior experience in the financial industry.
Somewhere in your talent pool of over a thousand engineers and contractors, the perfect candidates exist. But finding them is not a simple task. Managers spend valuable hours sifting through CVs, trying to remember who has what skills, and piecing together project histories. It’s a process that’s not just time-consuming — it’s fundamentally flawed.
And it creates a cascade of business risks:
- Senior managers spend valuable hours on administrative tasks instead of strategic work.
- Project kickoffs are delayed due to staffing bottlenecks.
- Client presentations contain outdated or inconsistent information about team capabilities.
- Suboptimal teams are formed while great candidates are overlooked.
The challenge isn’t just about matching skills to requirements. It’s about transforming a complex human search and decision process into a scalable, automated system that optimizes talent matching while dramatically reducing time-to-team. Let me show you how.
Reimagining Talent Matching with AI
What if your team assembly process could be as intuitive as having a conversation with your most experienced project manager, but with instant access to every detail about your talent pool? This is exactly what artificial intelligence, and specifically Retrieval-Augmented Generation (RAG), makes possible.
Our solution transforms project staffing from a manual hunt into an intelligent matching system that operates in two blocks:
- An AI-powered selection and ranking engine that combines intelligent retrieval with generative AI to match talent to requirements.
- An automated presentation generator that transforms the final selection into client-ready slides adapted to the specific project.
Speed alone isn’t what makes this solution so valuable — it’s also accuracy and reliability. Every recommendation comes with a clear rationale, backed by current data. No more relying on outdated information or gut feelings. Every match is traceable, every decision transparent.
And these are some of the key technical choices to power this solution and meet the client’s requirements:
- A hybrid retrieval system that combines full-text search and vector search for semantic matching beyond keywords. Databases like PostgreSQL (with the pgvector extension) and LanceDB are great options for this.
- An advanced large language model like OpenAI’s GPT-4o for intelligent processing and generation.
- Integrating the solution into the tools and platforms where the company’s team already works to facilitate adoption. For example, the solution is delivered as a chatbot directly within Microsoft Teams and includes real-time synchronization with SharePoint to ensure that all CVs and talent information remain up-to-date.
- And because we understand European business needs, compliance is built into the foundation. All processing occurs within EU-hosted Azure infrastructure, using OpenAI’s models in a GDPR-compliant configuration. Your data stays in Europe and your processes remain compliant.
Inside the Solution: How It Works
After the overview of the solution, let’s now go a bit deeper to understand the inner-workings of each component in more detail.
Data Processing and Management
There are two big challenges to solve here:
- Creating an optimized representation of the source documents (the 1000+ CVs and professional profiles) for the search and selection process.
- Making sure that this representation remains up to date as the source documents change.
In RAG applications, generally, the more complex the system and the search queries it needs to handle, the more advanced the required data processing. Rather than just breaking the documents down into chunks and embedding them, as it’s usually done in simpler RAG apps, our system demands a more sophisticated approach:
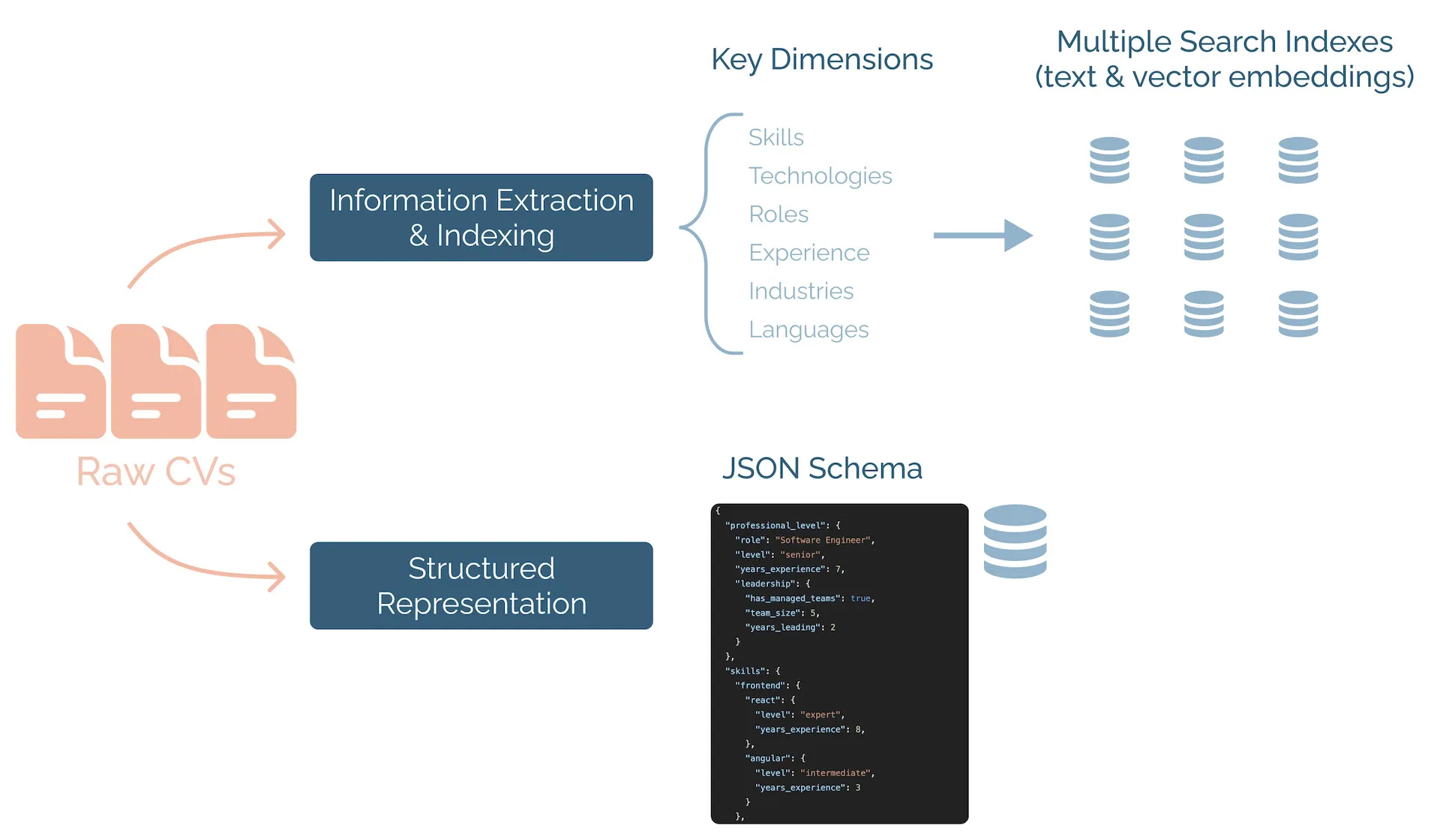
- Dimension-specific extraction: Instead of treating CVs as monolithic documents, we are going to extract and index information along the key dimensions of interest: skills, technologies, education, professional roles, experience, industries, languages, etc. This increases information density compared to the raw CVs and documents.
- Multiple search indexes: Create search indexes for each of the key dimensions that we can query separately and then combine together. Additionally, we are storing the information both as text for full-text search and encoded as a vector embeddings for semantic search.
- Structured representation: Transform each professional profile into a structured representation according to a specific JSON schema. This allows filtering and a more precise search than full-text or vector search. Here is an example of how this structured representation could look like:
{
"professional_level": {
"role": "Software Engineer",
"level": "senior",
"years_experience": 7,
"leadership": {
"has_managed_teams": true,
"team_size": 5,
"years_leading": 2
}
},
"skills": {
"frontend": {
"react": {
"level": "expert",
"years_experience": 8,
},
"angular": {
"level": "intermediate",
"years_experience": 3
}
},
"backend": {
"nodejs": {
"level": "advanced",
"years_experience": 6
}
}
},
"industries": {
"fintech": {
"years_experince": 3,
"num_projects": 4,
"roles": ["Frontend Software Engineer", "Frontend Lead"]
}
},
"languages": {
"English": "Native",
"Spanish": "C1"
}
}The second challenge is maintaining data freshness. To solve this, we are implementing a real-time synchronization system with SharePoint using webhooks. Whenever we receive notifications of document changes, we will perform the processing described above for new or updated CVs, and make sure to delete from the database and search indexes any obsolete data.
It’s also worth mentioning that periodic bulk processing might be a more convenient alternative for high-frequency update scenarios.
Selection & Ranking Engine
The selection engine implements a multi-stage search and ranking process that goes beyond simple keyword matching and semantic search. This is an overview of the steps involved:
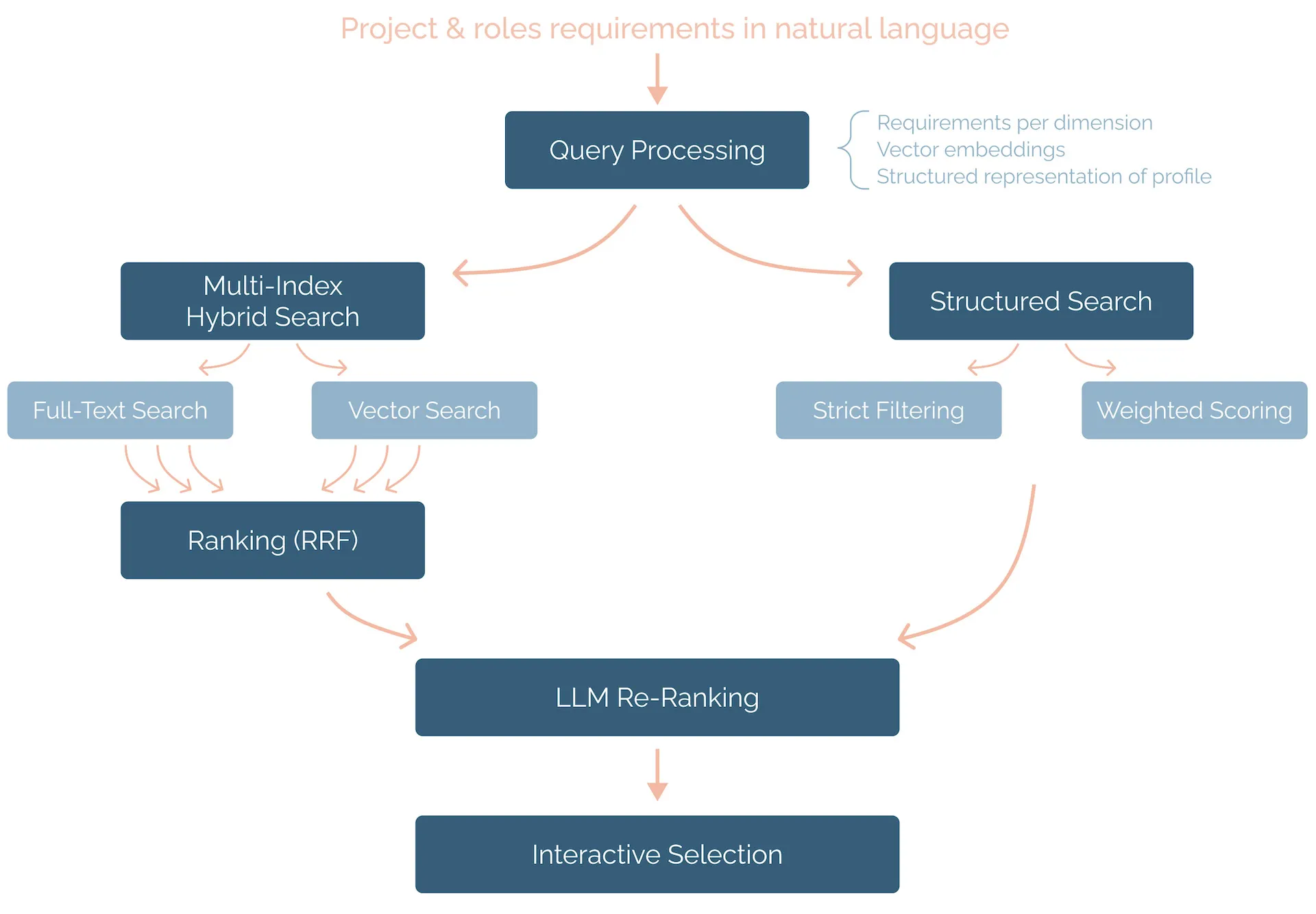
- Query processing: When the user provides the project and roles requirements in natural language, the first step is to perform query processing, analogous to the document processing described above. The main goal here is to bridge the search distance between the requirements query and the professional profiles information. This involves:
- Extracting requirements per dimension of interest.
- Generate dimension-specific search vector embeddings.
- Creating an ideal structured candidate profile according to the same JSON schema explained previously.
- Multi-index hybrid search: Perform parallel searches across the different search indexes corresponding to the key dimensions. The searches will be hybrid, combining full-text search and vector similarity search for semantic matching.
- Ranking: Combine the results of the different searches and return a final ranking of results (per wanted role), using a ranking algorithm like Reciprocal Rank Fusion (RRF). An interesting idea is to implement a weighted ranking, where different dimensions have different weights according to their importance for the candidate selection.
- Structured search and filtering: The previous vector and full-text searches can be combined with a more precise search and filtering using the structured JSON schema. This enables both hard constraints through strict filtering (e.g., “minimum 3 years React experience”, “senior level or above”) and soft constraints through a weighted scoring function that rewards desired attributes (e.g., “preferably fintech experience”, “ideally team leadership background”).
- LLM re-ranking: The final stage uses the large language model to perform an intelligent re-ranking of the retrieved candidates. The LLM analyzes all available information about both the candidates and project requirements to generate a final ranking with the top-k candidates for each role.
- Interactive final selection: The system presents multiple candidates per role to the user, including links to the full CVs and AI-generated justifications explaining each selection. This enables an iterative selection process where users can review recommendations, provide feedback, and adjust preferences until the optimal team is assembled.
Team Slides Generation
Once the final team selection has been confirmed by the user, the system automates the creation of a client-ready presentation. This process consists of two steps:
- The LLM analyzes the selected profiles and then synthesizes and customizes the most relevant information for the project, highlighting the key skills, experiences and achievements for each role.
- The system then automatically generates the slides for the client presentation using the generated content and a corporate PowerPoint template.
User Interface
The entire system is accessible through a simple chat interface in Microsoft Teams, seamlessly integrated into the company’s existing workflows. The interface is built using the Microsoft Bot Framework SDK and Azure AI Bot Service, with secure authentication handled by the Microsoft Identity Platform.
The user experience is intuitive and straightforward, with a natural three-step workflow:
- Describe the project requirements and desired roles in natural language.
- Review and refine the candidates selection interactively.
- Receive the automatically generated team presentation slides.
This simplicity in the user experience is worth emphasizing: the entire complexity of the RAG system remains completely hidden from end users, who only need to chat naturally about their projects and staffing requirements.
Business Impact and ROI
The shift from manual to AI-powered project-team matching delivers immediate, measurable improvements. The time reclaimed from manual processes translates directly to cost savings. What used to take hours of wading through CVs, trying to remember previous projects and preparing client slides can now be essentially completed in minutes. Managers can focus on high-impact activities instead.
But the real value goes beyond time savings. The system’s AI-powered evaluation considers many factors a human might miss, especially when dealing with hundreds of profiles. This means better matches, unexpected discoveries, and teams that truly align with project needs. The standardized matching process ensures justified decisions that stand up to scrutiny.
It also makes knowledge more accessible. No longer does team assembly depend on the collective memory of a few seasoned managers. No more “I think they worked on something similar last year.” Every project experience, every skill, and every success story becomes instantly searchable and actionable.
And with real-time SharePoint synchronization, decisions are always based on current information — no more outdated CVs or missed certifications.
But perhaps most importantly, this is just the beginning. By capturing human feedback on team selections, tracking performance metrics and analyzing actual outcomes, we can continuously refine and enhance the matching process. This practical feedback loop ensures the system grows more effective over time, adapting to the organization’s unique patterns and preferences. It’s not just a staffing tool — it’s the first step towards data-driven talent optimization.
If you have any questions, comments, or face similar challenges around intelligent process automation in your organization, I’d love to hear from you at [email protected].