Crea un chatbot con IA alimentado por tus datos
Implementación de un chatbot con RAG (Retrieval Augmented Generation) usando FastAPI, Redis y OpenAI
En un artículo anterior, “Retrieval Augmented Generation desde cero”, exploramos los fundamentos de los sistemas RAG construyendo, desde cero, una aplicación local en Python. Vimos conceptos clave como la carga de documentos, la segmentación de texto (chunking), los vectores embeddings y la búsqueda semántica. La aplicación que construimos era capaz de responder preguntas sobre la película Inception usando su guion como fuente de datos.
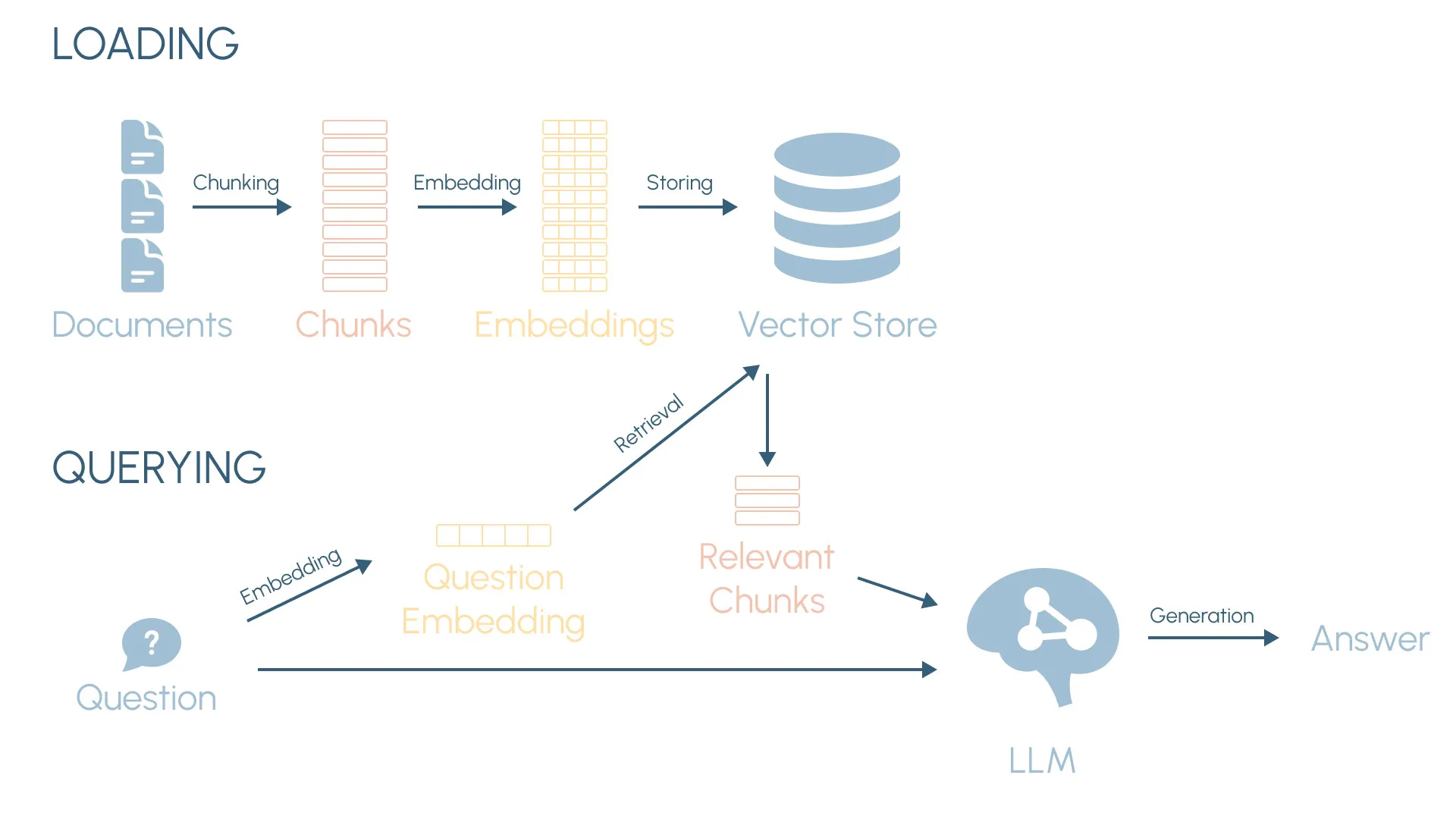
Ahora vamos a llevar todo esto al siguiente nivel. En este artículo, vamos a construir un chatbot con IA listo para producción que muestra cómo aplicar estos conceptos en un caso de uso real. Será un chatbot de tendencias tecnológicas basado en los últimos informes de instituciones como McKinsey, Deloitte, el Banco Mundial, el FEM y la OCDE.
Lo implementaremos como una aplicación web full-stack, con un backend en Python (que cubriremos aquí) y un frontend en React (que veremos en el siguiente artículo). Y la gran ventaja de este sistema es que se puede personalizar con tus propias fuentes de datos y adaptar a distintos casos de uso.
Además, usaremos técnicas y tecnologías más avanzadas para construir una aplicación lista para producción. Este es un resumen de lo que cubriremos:
- FastAPI para desarrollar la API del backend.
- Redis como base de datos vectorial ultrarrápida para búsqueda semántica y almacenamiento de las conversaciones.
- Los embeddings de OpenAI y GPT-4o como modelo de lenguaje (LLM) del chatbot.
- El uso de herramientas (tool calling) y la nueva funcionalidad de Structured Outputs de OpenAI.
- Memoria conversacional mediante el almacenamiento del historial de chats.
- Streaming de respuestas usando Server-Sent Events.
- Programación asíncrona en Python con asyncio.
- Un frontend en React (en el próximo artículo).
Las técnicas que veremos pueden aplicarse en múltiples dominios, desde asistentes tecnológicos hasta atención al cliente, análisis financiero o cualquier campo donde donde el acceso a información especializada y actualizada sea clave.
Todo el código de la aplicación está disponible en este repositorio de GitHub. Aunque intentaré explicar todo lo posible en este artículo, puedes consultar los detalles más específicos allí. Y si no estás familiarizado con algunos de los conceptos, te recomiendo revisar el artículo anterior que explica RAG desde cero.
Estructura del backend
Antes de profundizar en los detalles, echemos un vistazo a la estructura del backend para tener una visión general de cómo está organizada la aplicación:
backend/
│
├── app/
│ ├── assistants/
│ │ ├── assistant.py # Clase principal del asistente
│ │ ├── local-assistant.py # Clase del asistente para la aplicación local
│ │ ├── prompts.py # Prompts del asistente
│ │ └── tools.py # Contiene la herramienta QueryKnowledgeBaseTool
│ │
│ ├── utils/
│ │ ├── splitter.py # Segmentación de texto
│ │ └── sse_stream.py # Server-sent events
│ │
│ ├── api.py # Endpoints de FastAPI
│ ├── config.py # Configuración con Pydantic Settings
│ ├── db.py # Base de datos Redis
│ ├── export.py # Exportación de chats a JSON
│ ├── loader.py # Procesamiento de documentos y base de conocimiento
│ ├── main.py # Aplicación principal de FastAPI
│ └── openai.py # Funciones de OpenAI
│
└── pyproject.toml # Dependencias y configuración del proyectoCreación de la base de conocimiento
Lo primero que necesitamos en un chatbot basado en RAG es una base de conocimiento (knowledge base), que contiene la información necesaria para responder a las preguntas de los usuarios. Veamos la función principal que construye la base de conocimiento:
async def load_knowledge_base():
async with get_redis() as rdb:
await setup_db(rdb)
chunks = await process_docs()
await add_chunks_to_vector_db(rdb, chunks)La función get_redis() abre una conexión asíncrona con Redis (veremos Redis en la siguiente sección). Después configuramos la base de datos, procesamos los documentos (en nuestro caso, los informes tecnológicos en PDF) y almacenamos los fragmentos procesados junto con sus embeddings en la base de datos vectorial.
La función de procesamiento de documentos es similar a lo que hicimos en el artículo anterior RAG desde cero e incluye:
- Cargar y extraer el texto de los archivos PDF.
- Segmentar los documentos en fragmentos de texto más pequeños, con cierto solapamiento para preservar el contexto entre fragmentos.
- Convertir los fragmentos de texto en embeddings vectoriales (usando los embeddings de OpenAI) que codifican su significado.
- Almacenar los fragmentos de texto y los embeddings en la base de datos vectorial.
Aquí tienes una versión simplificada de todo este procesamiento:
async def process_docs(docs_dir=settings.DOCS_DIR):
docs = []
pdf_files = [f for f in os.listdir(docs_dir) if f.endswith('.pdf')]
for filename in tqdm(pdf_files):
file_path = os.path.join(docs_dir, filename)
text = extract_text(file_path)
doc_name = os.path.splitext(filename)[0]
docs.append((doc_name, text))
chunks = []
text_splitter = TextSplitter(chunk_size=512, chunk_overlap=150)
for doc_name, doc_text in docs:
doc_id = str(uuid4())[:8]
doc_chunks = text_splitter.split(doc_text)
for chunk_idx, chunk_text in enumerate(doc_chunks):
chunk = {
'chunk_id': f'{doc_id}:{chunk_idx+1:04}',
'text': chunk_text,
'doc_name': doc_name,
'vector': None
}
chunks.append(chunk)
vectors = []
for batch in batchify(chunks, batch_size=64):
batch_vectors = await get_embeddings([chunk['text'] for chunk in batch])
vectors.extend(batch_vectors)
for chunk, vector in zip(chunks, vectors):
chunk['vector'] = vector
return chunksSi tienes curiosidad sobre la funcionalidad de segmentación en TextSplitter, la vimos en el artículo anterior sobre RAG y también puedes consultar el código en detalle aquí.
Crear los embeddings vectoriales con OpenAI es tan sencillo como:
from openai import AsyncOpenAI
client = AsyncOpenAI(api_key=settings.OPENAI_API_KEY)
async def get_embeddings(input, model=settings.EMBEDDING_MODEL, dimensions=settings.EMBEDDING_DIMENSIONS):
res = await client.embeddings.create(input=input, model=model, dimensions=dimensions)
return [d.embedding for d in res.data]Base de datos Redis
Redis es una base de datos en memoria de alto rendimiento y muy versátil. Aunque es más conocida como sistema de caché, ha evolucionado mucho en los últimos años e incluye potentes extensiones para JSON y búsqueda (incluyendo búsqueda vectorial). También ofrece diferentes opciones de persistencia para garantizar la seguridad de los datos.
Si eres nuevo en Redis, sus guías de inicio rápido están muy bien para ponerte al día. También puedes echar un vistazo a los ejemplos de la librería para Python.
En nuestra aplicación, Redis desempeña un doble papel:
- Como base de datos vectorial para búsqueda semántica, permitiéndonos encontrar los fragmentos semánticamente más similares a las preguntas del usuario.
- Como base de datos general para el almacenamiento de las conversaciones.
Para poder almacenar vectores y realizar búsquedas vectoriales, necesitamos crear un índice en Redis:
async def create_vector_index(rdb):
schema = (
TextField('$.chunk_id', no_stem=True, as_name='chunk_id'),
TextField('$.text', as_name='text'),
TextField('$.doc_name', as_name='doc_name'),
VectorField(
'$.vector',
'FLAT',
{
'TYPE': 'FLOAT32',
'DIM': settings.EMBEDDING_DIMENSIONS,
'DISTANCE_METRIC': 'COSINE'
},
as_name='vector'
)
)
await rdb.ft('idx:vector').create_index(
fields=schema,
definition=IndexDefinition(prefix=['vector:'], index_type=IndexType.JSON)
)El índice es de tipo JSON. Además del vector embedding (vector) almacenamos otros metadatos como chunk_id, doc_name (útiles para citar fuentes) y el texto completo del fragmento en text. El prefijo 'vector:' indica que todos los objetos JSON deben almacenarse con claves que empiecen con ese prefijo para ser indexados.
Es importante mencionar que no es necesario indexar todos los campos cuando almacenas datos en Redis. Solo debes indexar aquellos campos que vayas a utilizar en las búsquedas, para que estas sean eficientes. Por ejemplo, el índice que utilizamos para almacenar los chats es mucho más simple, y solo incluye el campo created por si queremos obtener los últimos chats ordenados por fecha:
async def create_chat_index(rdb):
schema = (
NumericField('$.created', as_name='created', sortable=True),
)
await rdb.ft('idx:chat').create_index(
fields=schema,
definition=IndexDefinition(prefix=['chat:'], index_type=IndexType.JSON)
)Veamos ahora algunas de las funciones clave que interactúan con nuestra base de datos Redis. Esta es la función utilizada en la sección anterior para añadir fragmentos a la base de datos vectorial:
async def add_chunks_to_vector_db(rdb, chunks):
async with rdb.pipeline(transaction=True) as pipe:
for chunk in chunks:
pipe.json().set('vector:' + chunk['chunk_id'], Path.root_path(), chunk)
await pipe.execute()Esta función realiza la búsqueda semántica usando el algoritmo K-nearest neighbors (KNN) y devuelve los top_k fragmentos más similares:
async def search_vector_db(rdb, query_vector, top_k=settings.VECTOR_SEARCH_TOP_K):
query = (
Query(f'(*)=>[KNN {top_k} @vector $query_vector AS score]')
.sort_by('score')
.return_fields('score', 'chunk_id', 'text', 'doc_name')
.dialect(2)
)
res = await rdb.ft(VECTOR_IDX_NAME).search(query, {
'query_vector': np.array(query_vector, dtype=np.float32).tobytes()
})
return [{
'score': 1 - float(d.score),
'chunk_id': d.chunk_id,
'text': d.text,
'doc_name': d.doc_name
} for d in res.docs]Observa cómo calculamos la puntuación de similitud como 1 - float(d.score) porque la puntuación que devuelve la búsqueda es la distancia coseno (cuanto menor sea la distancia coseno, mayor será la similitud con la consulta del usuario). Y queremos obtener los top_k fragmentos más similares (los 10 primeros en nuestra aplicación). Ten en cuenta también que Redis requiere que el vector de consulta sea un array de bytes, por eso usamos np.array() y tobytes() de Numpy.
Finalmente, estas son las funciones utilizadas para crear chats, comprobar si existe un chat, añadir nuevos mensajes a un chat y recuperar los últimos n mensajes de un chat concreto (útil para la memoria conversacional):
async def create_chat(rdb, chat_id, created):
chat = {'id': chat_id, 'created': created, 'messages': []}
await rdb.json().set('chat:' + chat_id, Path.root_path(), chat)
return chat
async def chat_exists(rdb, chat_id):
return await rdb.exists('chat:' + chat_id)
async def add_chat_messages(rdb, chat_id, messages):
await rdb.json().arrappend('chat:' + chat_id, '$.messages', *messages)
async def get_chat_messages(rdb, chat_id, last_n=None):
if last_n is None:
messages = await rdb.json().get('chat:' + chat_id, '$.messages[*]')
else:
messages = await rdb.json().get('chat:' + chat_id, f'$.messages[-{last_n}:]')
return [{'role': m['role'], 'content': m['content']} for m in messages] if messages else []Endpoints de la API
Para crear el backend usamos FastAPI, un framework moderno y rápido para construir APIs con Python. En nuestra aplicación, hay dos endpoints principales:
- Crear una nueva sesión de chat.
- Enviar un mensaje y obtener la respuesta del chatbot en una sesión de chat concreta.
Veamos los endpoints en código:
from fastapi import APIRouter, Depends, HTTPException
router = APIRouter()
@router.post('/chats')
async def create_new_chat(rdb = Depends(get_rdb)):
chat_id = str(uuid4())[:8]
created = int(time())
await create_chat(rdb, chat_id, created)
return {'id': chat_id}
@router.post('/chats/{chat_id}')
async def chat(chat_id: str, chat_in: ChatIn):
rdb = get_redis()
if not await chat_exists(rdb, chat_id):
raise HTTPException(status_code=404, detail=f'Chat {chat_id} does not exist')
assistant = RAGAssistant(chat_id=chat_id, rdb=rdb)
sse_stream = assistant.run(message=chat_in.message)
return EventSourceResponse(sse_stream, background=rdb.aclose)El segundo endpoint chat crea una instancia de la clase RAGAssistant, que incluye la lógica central de nuestro chatbot, como veremos en breve. Llama al método run() con el mensaje del usuario y usa Server-Sent Events (SSE) para enviar las respuestas del asistente al cliente mediante streaming en tiempo real. Para ello, utilizamos EventSourceResponse de la librería sse-starlette.
Fíjate también en que estamos usando el sistema de inyección de dependencias de FastAPI en rdb = Depends(get_rdb) para gestionar las conexiones con Redis. Usando la instrucción yield, abrimos la conexión cuando comienza la petición y la cerramos cuando finaliza:
async def get_rdb():
rdb = get_redis()
try:
yield rdb
finally:
await rdb.aclose()⚠️ Debido a una limitación con las respuestas en streaming de FastAPI después de la versión 0.106, no podemos usar una dependencia con yield para cerrar la conexión Redis en el segundo endpoint, así que lo hacemos usando una tarea en segundo plano en EventSourceResponse.
Con los endpoints definidos, crear una aplicación FastAPI es simple:
from fastapi import FastAPI
app = FastAPI()
app.include_router(router)Clase RAG Assistant
La clase RAGAssistant contiene la lógica central de nuestro chatbot RAG. Gestiona las conversaciones de los usuarios, almacena el historial de chat, consulta la base de conocimiento para obtener información relevante y utiliza el LLM con Retrieval Augmented Generation para responder a las preguntas de los usuarios.
La clase se inicializa así:
from openai import pydantic_function_tool
class RAGAssistant:
def __init__(self, chat_id, rdb, history_size=4, max_tool_calls=3):
self.chat_id = chat_id
self.rdb = rdb
self.sse_stream = None
self.main_system_message = {'role': 'system', 'content': MAIN_SYSTEM_PROMPT}
self.rag_system_message = {'role': 'system', 'content': RAG_SYSTEM_PROMPT}
self.tools_schema = [pydantic_function_tool(QueryKnowledgeBaseTool)]
self.history_size = history_size
self.max_tool_calls = max_tool_callsUn resumen rápido de estos atributos:
chat_id: ID de la sesión de chat actual.rdb: Conexión a la base de datos Redis.sse_stream: Objeto que gestiona el streaming de la respuesta en tiempo real.main_system_messageyrag_system_message: Prompts de sistema que guían el comportamiento del asistente.tools_schema: Herramientas disponibles para el asistente, en nuestro caso soloQueryKnowledgeBaseTool. La funciónpydantic_function_toolgenera el esquema JSON de la herramienta.history_size: Número de mensajes anteriores a incluir en cada interacción de conversación.max_tool_calls: Número máximo de llamadas a herramientas por interacción.
Una de las características clave de nuestro chatbot es su capacidad para realizar streaming de las respuestas. Esto se consigue mediante una combinación de programación asíncrona y server-sent events (SSE). Echemos un vistazo al método principal run (utilizado en el endpoint chat):
def run(self, message):
self.sse_stream = SSEStream()
asyncio.create_task(self._handle_conversation_task(message))
return self.sse_streamCuando llega un nuevo mensaje del usuario, el asistente crea un objeto SSEStream que se encarga de crear una cola y gestionar el envío de la respuesta. A continuación, crea una tarea asíncrona con asyncio que gestiona toda la lógica de la conversación y devuelve inmediatamente el sse_stream. Esto permite comenzar a transmitir la respuesta al cliente en cuanto se generan los primeros fragmentos de texto, en lugar de esperar a que se complete todo el proceso.
En lugar de hacer await a self._handle_conversation_task(message) en el método run, lo lanzamos como una tarea concurrente. Así, la gestión de la conversación y el streaming de la respuesta pueden ejecutarse simultáneamente.
El método _handle_conversation_task ejecuta la lógica de la conversación, gestiona posibles errores y se asegura de que el sse_stream se cierre al final:
async def _handle_conversation_task(self, message):
try:
await self._run_conversation_step(message)
except Exception as e:
print(f'Error: {str(e)}')
# Other error handling
finally:
await self.sse_stream.close()La función _run_conversation_step es donde implementamos RAG, realizamos búsquedas en la base de conocimiento y usamos el LLM para generar respuestas al usuario. Es probablemente la parte más importante del chatbot y vamos a analizarla en detalle en la siguiente sección.
Implementando RAG con herramientas y respuestas estructuradas
En mi última entrada de blog, “Structured Outputs de OpenAI para RAG y extracción de datos”, exploré la nueva funcionalidad de Structured Outputs de OpenAI, que permite asegurar que las respuestas del modelo cumplan un esquema JSON concreto. El artículo muestra cómo definir los esquemas usando Pydantic y algunas funciones útiles proporcionadas por el SDK de Python de OpenAI. También incluye algunos ejemplos de cómo usar respuestas estructuradas en aplicaciones RAG, con y sin streaming.
Nuestro chatbot de IA utiliza estas mismas técnicas, así que si quieres profundizar más, te recomiendo leer el artículo.
El proceso RAG se integra en el flujo de la conversación a través del método _run_conversation_step de la clase RAGAssistant:
async def _run_conversation_step(self, message):
user_db_message = {'role': 'user', 'content': message, 'created': int(time())}
chat_messages = await get_chat_messages(self.rdb, self.chat_id, last_n=self.history_size)
chat_messages.append({'role': 'user', 'content': message})
assistant_message = await self._generate_chat_response(
system_message=self.main_system_message,
chat_messages=chat_messages,
tools=self.tools_schema
)
tool_calls = assistant_message.tool_calls
if tool_calls:
chat_messages.append(assistant_message)
assistant_message = await self._handle_tool_calls(tool_calls, chat_messages)
assistant_db_message = {
'role': 'assistant',
'content': assistant_message.content,
'tool_calls': [
{'name': tc.function.name, 'arguments': tc.function.arguments} for tc in tool_calls
],
'created': int(time())
}
await add_chat_messages(self.rdb, self.chat_id, [user_db_message, assistant_db_message])Un desglose de lo que hace esta función:
- Crea un objeto con el mensaje recibido del usuario y una marca temporal para el almacenamiento en la base de datos.
- Obtiene los últimos (
self.history_size) mensajes del chat de la base de datos para la sesión actual (con IDchat_id) y añade el nuevo mensaje del usuario. - Llama al LLM (GPT-4 de OpenAI) con el mensaje de sistema, las herramientas disponibles y el historial del chat para generar la respuesta del asistente. El LLM decide entonces si necesita utilizar una herramienta para responder adecuadamente a la pregunta del usuario. En nuestro caso solo estamos proporcionando la herramienta
QueryKnowledgeBaseTool, que permite realizar búsquedas en la base de conocimiento. - Si la respuesta del asistente contiene llamadas a herramientas, utiliza las herramientas y genera una nueva respuesta del asistente incorporando los resultados de las herramientas. En nuestro chatbot, esto significa responder a las preguntas del usuario con la información relevante obtenida de la base de conocimiento.
- Crea un objeto con el mensaje final del asistente y añade tanto el mensaje inicial del usuario como este mensaje del asistente al historial del chat en la base de datos.
Si tienes curiosidad, este es el prompt de sistema que estamos usando:
MAIN_SYSTEM_PROMPT = """
You are a knowledgeable assistant specialized in answering questions about new technology trends, their applications in various sectors and their broader impacts.
You have access to the 'QueryKnowledgeBaseTool,' which includes technology reports from the world's leading institutions.
Use this tool to query the knowledge base and answer user questions.
Do not rely on prior knowledge or make answers up.
Always use the provided 'QueryKnowledgeBaseTool' to ensure your answers are grounded in the most up-to-date and accurate information available.
If a user's question seems unrelated, try to find a relevant technology angle.
Only if the question is completely completely outside the scope of technology, kindly remind the user of your specialization.
"""El método _generate_chat_response llama al LLM y gestiona el streaming de la respuesta:
async def _generate_chat_response(self, system_message, chat_messages, **kwargs):
messages = [system_message, *chat_messages]
async with chat_stream(messages=messages, **kwargs) as stream:
async for event in stream:
if event.type == 'content.delta':
await self.sse_stream.send(event.delta)
final_completion = await stream.get_final_completion()
assistant_message = final_completion.choices[0].message
return assistant_messageEste método comprueba cada fragmento en el stream de respuesta generado por el LLM. Si es de tipo 'content.delta' (nuevo fragmento de texto), lo envíamos al cliente en tiempo real usando el objeto sse_stream. Una vez finalizada la generación, llamamos al método get_final_completion para obtener la respuesta completa, incluyendo las llamadas a herramientas que el modelo haya decidido utilizar.
La función chat_stream básicamente encapsula la función client.beta.chat.completions.stream() proporcionada por el SDK de Python de OpenAI. Si quieres saber más sobre los detalles del streaming con respuestas estructuradas, consulta esta sección de mi último artículo.
Como mencionamos anteriormente, proporcionamos una única herramienta al asistente para consultar la base de conocimiento. Definimos la herramienta con un modelo de Pydantic:
from pydantic import BaseModel, Field
class QueryKnowledgeBaseTool(BaseModel):
"""Query the knowledge base to answer user questions about new technology trends, their applications and broader impacts."""
query_input: str = Field(description='The natural language query input string. The query input should be clear and standalone.')
async def __call__(self, rdb):
query_vector = await get_embedding(self.query_input)
chunks = await search_vector_db(rdb, query_vector)
formatted_sources = [f'SOURCE: {c['doc_name']}\n"""\n{c['text']}\n"""' for c in chunks]
return f"\n\n---\n\n".join(formatted_sources) + f"\n\n---"La herramienta QueryKnowledgeBaseTool incluye un método __call__ para hacerla invocable. Una vez instanciada con la consulta a realizar (query_input) en lenguaje natural, la podemos llamar para consultar la base de conocimiento y obtener los fragmentos más relevantes para esa consulta. En concreto, la herramienta hace lo siguiente:
- Convierte la consulta en un vector embedding que codifica su significado.
- Busca en la base de datos vectorial Redis para recuperar los 10 fragmentos semánticamente más similares.
- Devuelve los fragmentos relevantes formateados e incluyendo para cada uno el nombre del documento para poder citar la fuente.
Si queremos que el LLM llame a nuestra herramienta, necesitamos proporcionar un esquema JSON que describa lo que hace la herramienta y qué parámetros se requieren para llamarla, según el formato especificado por OpenAI. La función pydantic_function_tool del SDK de OpenAI (que usamos en la inicialización del asistente) convierte automáticamente cualquier modelo de Pydantic en el esquema JSON requerido:
self.tools_schema = [pydantic_function_tool(QueryKnowledgeBaseTool)]Finalmente, veamos qué hace el método _handle_tool_calls:
async def _handle_tool_calls(self, tool_calls, chat_messages):
for tool_call in tool_calls[:self.max_tool_calls]:
kb_tool = tool_call.function.parsed_arguments
kb_result = await kb_tool(self.rdb)
chat_messages.append(
{'role': 'tool', 'tool_call_id': tool_call.id, 'content': kb_result}
)
return await self._generate_chat_response(
system_message=self.rag_system_message,
chat_messages=chat_messages,
)Un detalle clave aquí es que, como estamos usando la funcionalidad de respuestas estructuradas y usando Pydantic para definir la herramienta, la librería de OpenAI automáticamente convierte cualquier llamada a herramientas en instancias de nuestro modelo QueryKnowledgeBaseTool. Esto ocurre gracias a la función client.beta.chat.completions.stream() mencionada anteriormente.
Podemos encontrar esta instancia de QueryKnowledgeBaseTool, con el parámetro query_input incluido, en tool_call.function.parsed_arguments. Y como la hemos hecho “invocable” con __call__, basta con llamarla para realizar la consulta a la base de conocimiento.
A continuación añadimos un nuevo “mensaje de herramienta” al chat que contiene el resultado de la herramienta (los 10 fragmentos relevantes formateados) y llamamos al método _generate_chat_response de nuevo para generar la respuesta final con esta nueva información. El LLM puede entonces usar este resultado de la herramienta como contexto para responder a la pregunta del usuario. Esta es la idea central de la técnica de Retrieval-Augmented Generation.
Observa también que estamos usando un mensaje de sistema diferente para esta nueva generación con el LLM (self.rag_system_message), más centrado en el proceso RAG:
RAG_SYSTEM_PROMPT = """
You are a knowledgeable assistant specialized in answering questions about new technology trends, their applications in various sectors and their broader impacts.
Use the sources provided by the 'QueryKnowledgeBaseTool' to answer the user's question. You must only use the facts from the sources in your answer.
Make sure to reference and include relevant excerpts from the sources to support your answers.
When providing an answer, mention the specific report from which the information was retrieved (e.g., "According to the [Report Name], ...").
Your answers must be accurate and grounded on truth.
If the information needed to answer a question is not available in the sources, say that you don't have enough information and share any relevant facts you find.
"""Este enfoque es muy interesante para construir chatbots y aplicaciones basadas en LLM más complejas. En lugar de un único LLM con un único mensaje de sistema y herramientas, puedes combinar varios agentes con diferentes prompts de sistema y distintas herramientas, cada uno especializado en una tarea concreta.
Streaming de respuestas con Server-Sent Events
Normalmente, es el cliente el que debe enviar una petición para recibir datos del servidor. Sin embargo, en nuestro chatbot de IA, queremos que el servidor envíe datos de forma asíncrona al cliente, enviando cada fragmento de texto a medida que esté disponible. Esto hace que la aplicación sea más rápida y ofrezca una mejor experiencia de usuario.
Un posible enfoque es usar WebSockets, que crean una conexión bidireccional entre el cliente y el servidor. Sin embargo, para nuestro caso de uso, hay un enfoque más simple que funciona igual de bien y puede implementarse directamente usando HTTP: Server-Sent Events (SSE).
Con Server-Sent Events, el servidor puede enviar datos de forma asíncrona al cliente una vez establecida la conexión HTTP, que es justo lo que necesitamos. Para implementarlo en Python con FastAPI, utilizamos la librería sse-starlette.
Implementar SSE en FastAPI es tan simple como proporcionar al EventSourceResponse de sse-starlette un generador asíncrono que será la fuente de los datos a transmitir:
from sse_starlette.sse import EventSourceResponse
async def sse_endpoint():
return EventSourceResponse(generator)En nuestro chatbot, usamos una clase SSEStream que simplifica el proceso de enviar datos al stream desde distintas partes de la aplicación:
import asyncio
from sse_starlette import ServerSentEvent
class SSEStream:
def __init__(self) -> None:
self._queue = asyncio.Queue()
self._stream_end = object()
def __aiter__(self):
return self
async def __anext__(self):
data = await self._queue.get()
if data is self._stream_end:
raise StopAsyncIteration
return ServerSentEvent(data=data)
async def send(self, data):
await self._queue.put(data)
async def close(self):
await self._queue.put(self._stream_end)Estos son los puntos clave de la implementación:
- La clase usa una cola de asyncio para almacenar y gestionar los datos del stream.
- El método
sendañade nuevos datos a la cola. - El método
closecierra el stream añadiendo el objeto “centinela”_stream_end. - Los métodos
__aiter__y__anext__permiten que la clase se use como un generador asíncrono, extrayendo datos de la cola y enviándolos como eventos SSE hasta encontrar el objeto_stream_end. Eso es lo queEventSourceResponseutiliza para enviar los datos a medida que están disponibles.
Con todo esto en mente, ahora debería estar más claro cómo se integra el streaming en nuestra aplicación. Resumiendo lo que hemos visto en secciones anteriores:
- Creamos el stream en el método
runde la claseRAGAssistant:self.sse_stream = SSEStream(). - Ejecutamos
_handle_conversation_taskde forma concurrente para procesar la lógica de la conversación al mismo tiempo que hacemos streaming de la respuesta. - Devolvemos el stream al endpoint
chatde FastAPI para que empiece inmediatamente el streaming al cliente conreturn EventSourceResponse(sse_stream). - En el método
_generate_chat_responsedeRAGAssistant, cuando recibimos nuevos fragmentos de la respuesta del LLM, los enviamos al cliente en tiempo real medianteawait self.sse_stream.send(event.delta).
Conclusión
Hemos explorado en detalle los bloques y el código necesario para crear un chatbot con IA alimentado por tus propios datos y listo para producción. En el próximo artículo, construiremos la interfaz de usuario del chatbot en React.
Si quieres profundizar más, todo el código está disponible en el repositorio de GitHub. En el README encontrarás instrucciones para instalar y ejecutar tanto la aplicación full-stack como una versión local para hacer pruebas desde el terminal. Puedes personalizar fácilmente el sistema con tus propias fuentes de datos y montar chatbots para otros casos de uso.
También es importante señalar que la implementación RAG actual tiene algunas limitaciones. Los casos de uso más avanzados pueden requerir técnicas adicionales como: búsqueda híbrida (combinando búsqueda vectorial y por palabras clave), procesamiento y descomposición de consultas, filtrado con metadatos, re-ranking y RAG recursivo.
Si tienes alguna pregunta, comentario, o te gustaría implementar aplicaciones similares basadas en IA en tu empresa, puedes escribirme a [email protected].